Quality Score Worker
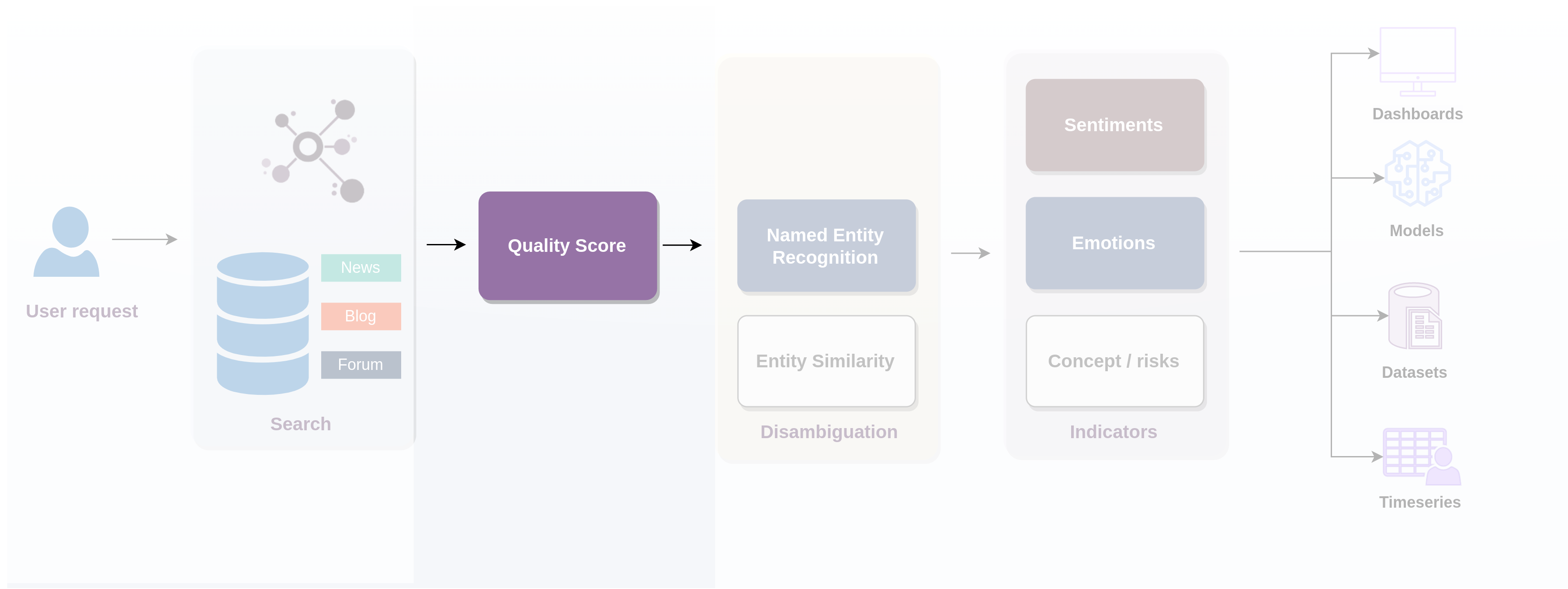
The Quality Score worker allows you to leverage TextReveal® quality score module so as to filter out noisy or unreadable documents according to a definable threshold.
The quality-score worker is restricted to certain languages,
see the Language Support page for more information
Definition
The Quality Score is a readability score provided at the document level. Is an indicator of the difference between a document and a set of reference texts to provide a readability value between 0 and 100. To calculate the quality score, the following are used:
-
Specific key performance indicators (KPIs) for each language group
-
Specific reference texts for each site type
The quality score operates at the topological level. It has no semantic feature and therefore is not fit to detect inappropriate document such as adult content.
Reference texts
Reference texts are documents that we consider to be the baseline for good readability documents. There are three groups of them which correspond to the site type currently available in SESAMm's data warehouse:
- News
- Blogs
- Discussions
KPIs
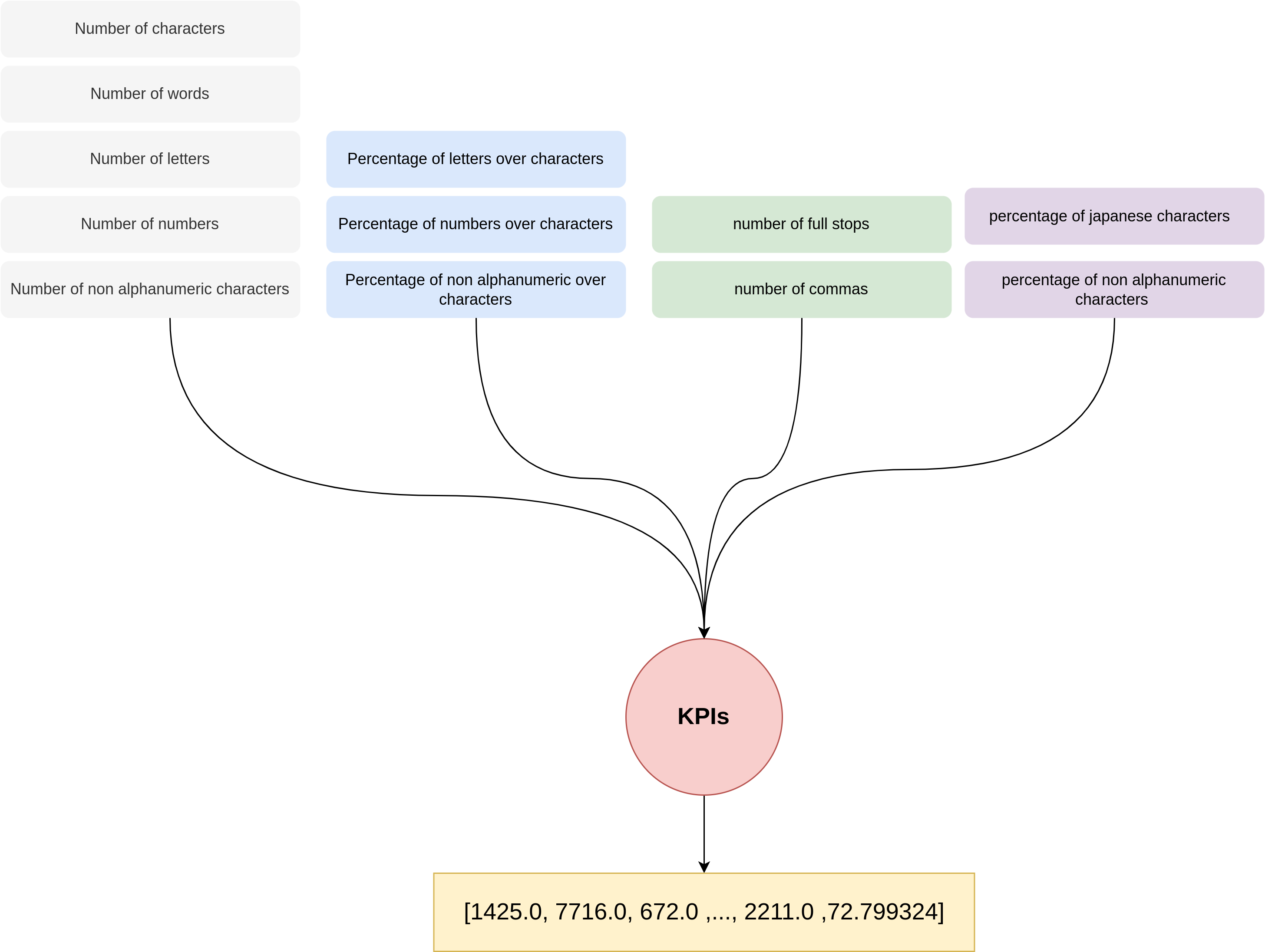
KPIs are statistical values computed from a document (such as number of char, number of sentences, etc). Human language is complex and depending on the language writing specificity may differ. Considering three differences we defined two main language groups which we called European languages, Japanese and Chinese languages ( Chinese and Japanese ).
There are currently two groups of KPIs including European language group and Chinese and Japanese language group.
| European languages | Chinese and japanese | |
|---|---|---|
| KPIs |
|
|
The group names do not reflects the geographical original area of languages. For example we considered Korean to be into the group European languages because it uses “European” punctuation and every words are separated with a blank space like European languages.